本篇概述:大概有几篇是关于pixiv关注画师的作品抓取的思路和代码,后面大概还会有p站个人收藏的爬虫(这个比较简单)

1、pixiv介绍
Pixiv登录绕过——2020.7.22更新
使用Selenium获取在Chrome浏览器上登录的Pixiv账号的cookie,从而绕过Google V3人机验证
链接:http://00102400.xyz/blog/2019/08/29/pixiv-new-login/
nginx+ 改host上P站教程——2019.5.24更新
已失效——2020.7.22
- 下载上面链接中的压缩包,解压
复制
hosts文件中的代码,追加到当前电脑的hosts文件中当前电脑的
hosts文件在C:\Windows\System32\drivers\etc目录下,如果没找到的话可以搜索一下或者用everything软件(强烈建议!)进行搜索.
- 打开
调试工具(这个功能全).bat
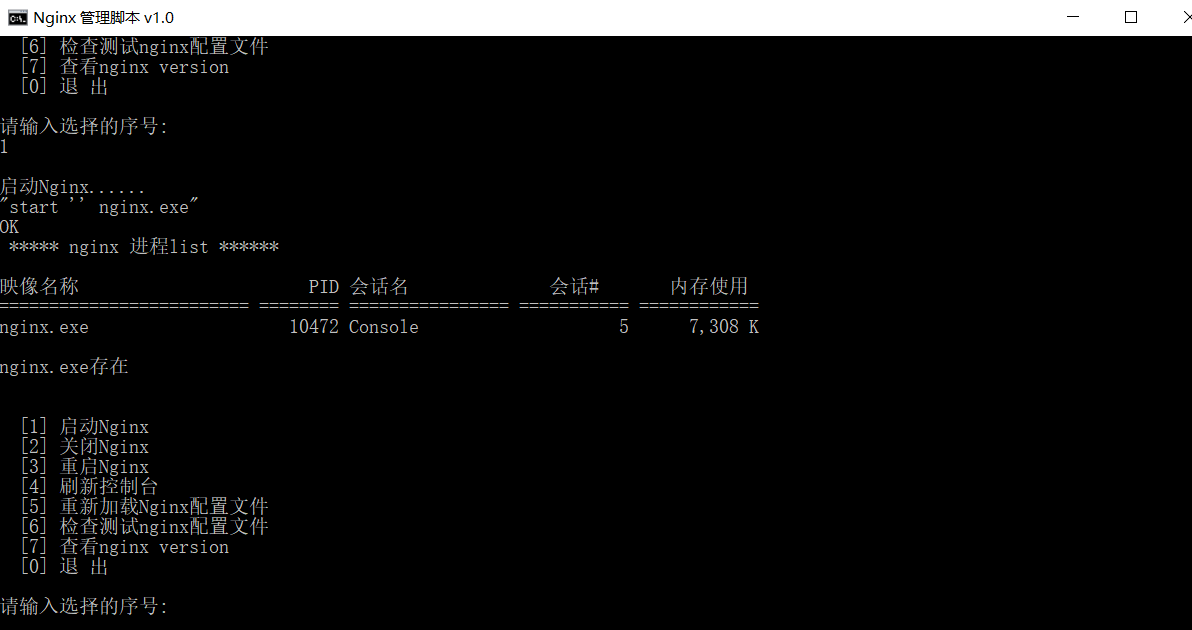
选择对应的数字序号
- Tip
- 如果正常启动不行的话,可以尝试以下代码
1 | netstat -aon | findstr ":443" |
- 或者手动修改nginx的端口,具体修改流程百度
2、Target
- 登录账号关注的画师的作品
- 思路:
- 首先是模拟登录(PC 用过 pixiv 的同学都知道在未登录的时候 pixiv 会对用户做一些限制,所以我们要先模拟登录)
- 其次保持会话连接(可以考虑 cookie 保存,这里采用的是 requests 的 session 会话连接)
- (基于图片网站,可能是动态加载,那么需要分析接口或者是 selenium 模拟)
- 最后才进行网页内容分析,然后抓取保存下来
3、登录模拟实现流程
一、查找登录接口
- 第一次找关于登录接口的时候,一个login都没看到,只看到一个 www.pixiv.net ,可惜是get请求的页面。
- 在拜读了 Chrome使用技巧 、Chrome开发者工具使用小技巧 后,算是对 chrome 的调试工具有个大概了解的印象,知道了 preserve log 勾选后,可以保留网络日志,于是发现了真正的登录请求
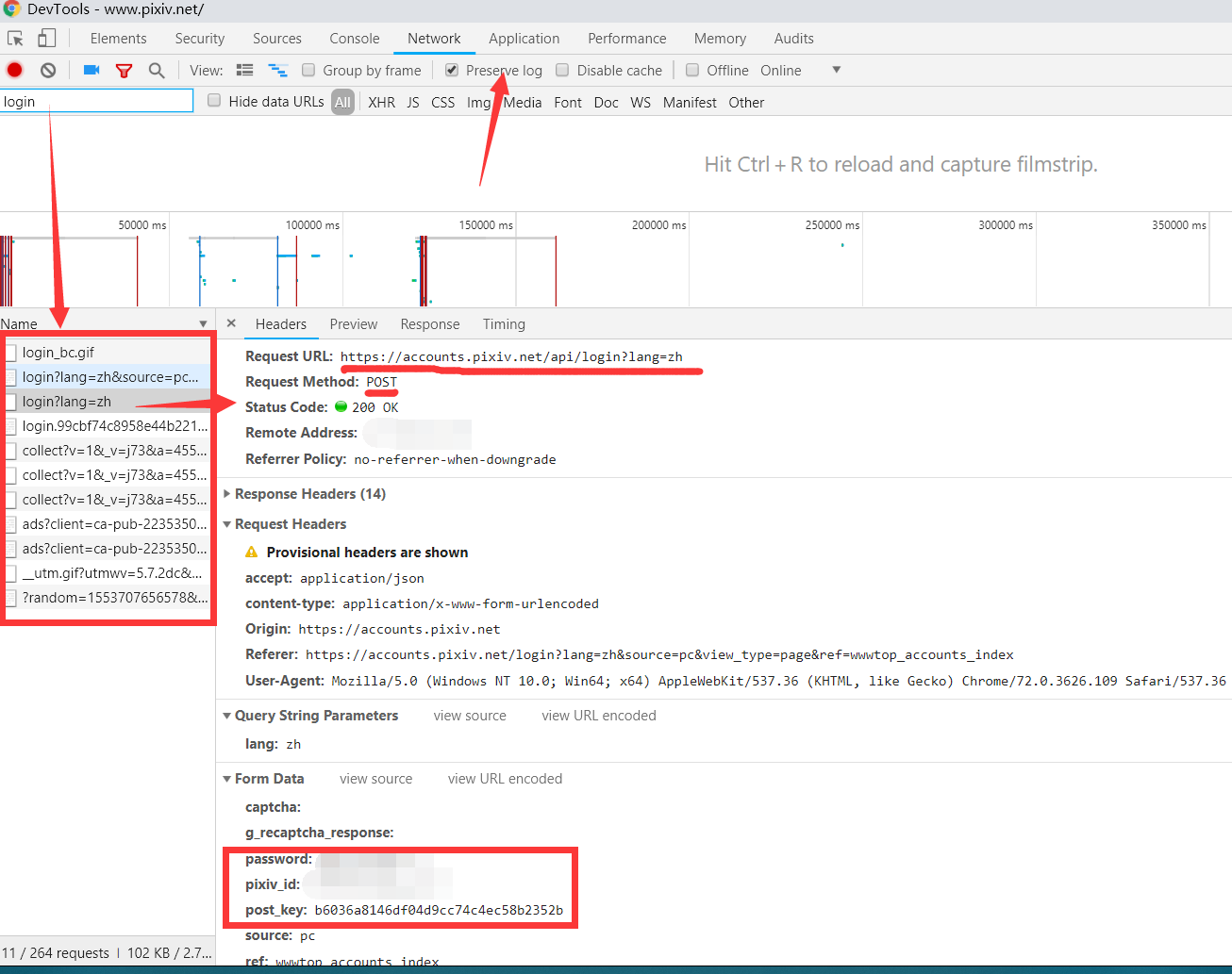
分析参数
password:个人密码
pixiv_id:个人id
post_key:不明字符串
source:pc即电脑端(截图没截全,把return_to漏掉了。。。)
return_to:是登录成功后跳转的页面,这个可以自己填,貌似默认是 https://www.pixiv.net/
那么接下来就是找post_key了
- 首先pixiv非常友好,所以应该不是js加密,而是在页面中随机生成的。
1 | # 其次在点击登录的时候就跳转 url1 ↓ |
F12 打开,在 Elements 中 Ctrl + F 查看 post_key
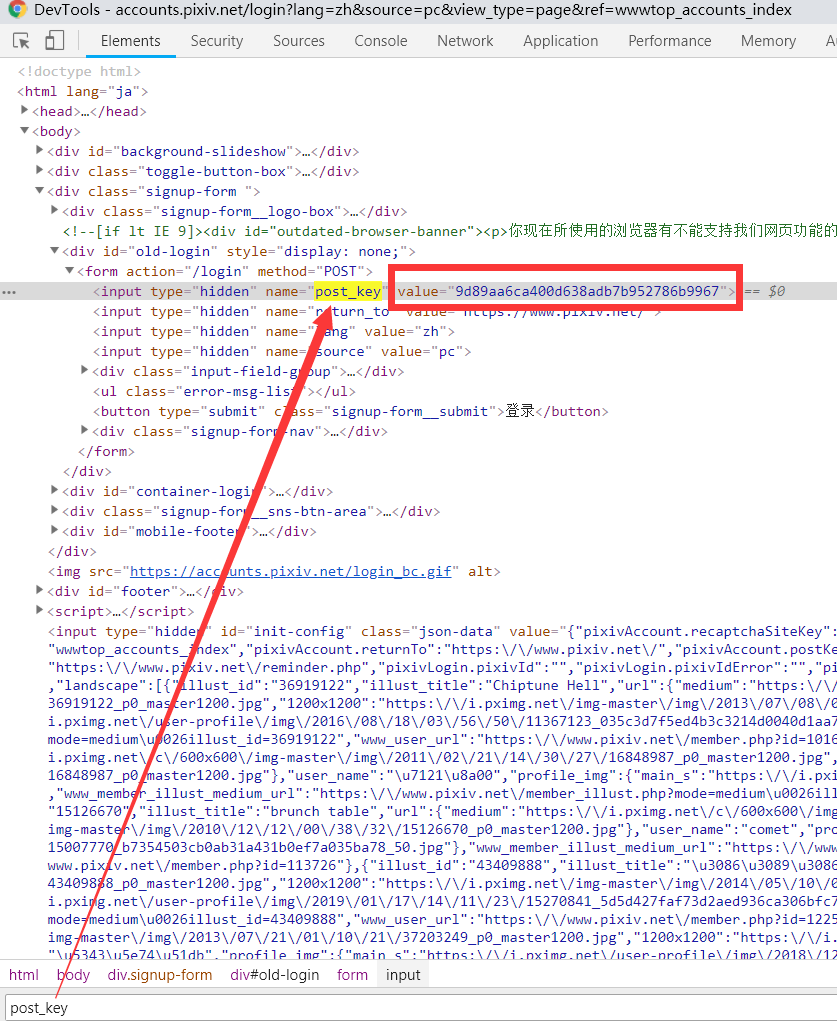
接下来用 BeautifulSoup 匹配
1 | self.post_key = post_key_soup.find('input') ['value'] |
接着向 url2 发去 post 请求
1 | data = { |
登录代码
0702更新代码,
1 | import requests |
顺便吐槽下 HTTPS 的证书报警问题
1 | from requests.packages.urllib3.exceptions import InsecureRequestWarning #强制取消警告 |
4、最后
先到这吧,后面继续写解析关注画师页面(页数),寻找数据接口,单图动图多图下载估计写不到了
へ( ̄  ̄;へ)